
Building the infrastructure to close the gap between AI deployment and AI accountability

“By the time you have an AI governance committee review of your AI solutions, it’s already out of date.”
Healthcare organizations are deploying AI at a pace that governance has not kept up with. That is not a criticism of any particular organization. It is a structural problem that hasn’t been solved yet. The frameworks available today were built around the idea that you evaluate an AI tool before you deploy it, document what you found, and move on.
What they are not built for is the reality that AI systems continue to change after deployment. Models drift. Vendors push updates. Regulatory requirements evolve. And the clinical environment the tool was trained on may look nothing like the one it is operating in days or even weeks later.
Jennifer Shannon, MD, is a physician, child psychiatrist, and co-founder and Chief Medical Officer of GLACIS, a DiMe partner and company building what she describes as runtime assurance infrastructure for AI in healthcare and beyond. She has spent years watching this mismatch play out in clinical practice, and GLACIS was built to address that gap.
The problem with snapshots
When Shannon talks about AI governance today, she keeps coming back to one word: “static.”
Most governance today relies on point-in-time reviews and checklists. A committee evaluates a tool, approves it, and the organization moves forward. But by the time that review concludes, the model may have often already changed, vendors release updates. The regulatory landscape shifts. A committee review cycle that might happen quarterly or even monthly simply cannot detect what is happening at the inference layer, the moment when the AI is actually making a decision about a real patient in real time.
Shannon draws a useful distinction between three layers of governance that she believes most organizations conflate. There is the data and model layer, which asks whether the model is performing accurately in aggregate. There is the application layer, which asks whether the product is functioning as designed. And then there is the runtime layer, which asks what is actually happening in the specific moment a clinician is using the tool with a specific patient. That third layer is the one she says nobody is adequately monitoring.
“Right now, many clinicians don’t have any visibility into how an AI solution is actually working when they are using it,” Shannon says. “Is it performing as originally designed? Is the model drifting? As a physician myself, right now, our option is, I just have to trust the vendor.”
The liability problem is already here
Shannon’s concerns about the runtime layer are not theoretical. They come from her own experience.
She describes a situation where an ambient scribe tool hallucinated a prescription she had not written, documenting that she had ordered a mood stabilizer for a patient with PTSD. The medication in question has no clinical indication for that condition. If a subsequent clinician had followed that note without scrutinizing it, the consequences could have been serious. Shannon caught the error because she happened to go back and check the transcript. Most clinicians, managing full patient panels and hundreds of pages of AI-generated documentation per day, would not.
Healthcare has quietly accepted an accountability structure in which the licensed professional at the end of the chain is responsible for catching every error, no matter how fast documentation moves or how opaque AI’s reasoning is. Vendors call it “human in the loop.” Shannon calls it what it is: liability that sits entirely with the clinician, backed by no independent record of what the AI actually did.
The question of who can go back and reconstruct what an AI system was doing at the exact moment of a specific clinical interaction, whether the safety controls were active, whether the model had drifted, whether a hallucination occurred, and why, is one that most health systems currently cannot answer. That is not a minor documentation gap. It is a patient safety problem. And as litigation around AI-assisted clinical decisions begins to surface, it is becoming a legal problem too.
GLACIS was built to make that reconstruction possible and to make sure the system’s ability to catch these problems improves continuously, not just when someone remembers to update a checklist.
What runtime assurance looks like in practice
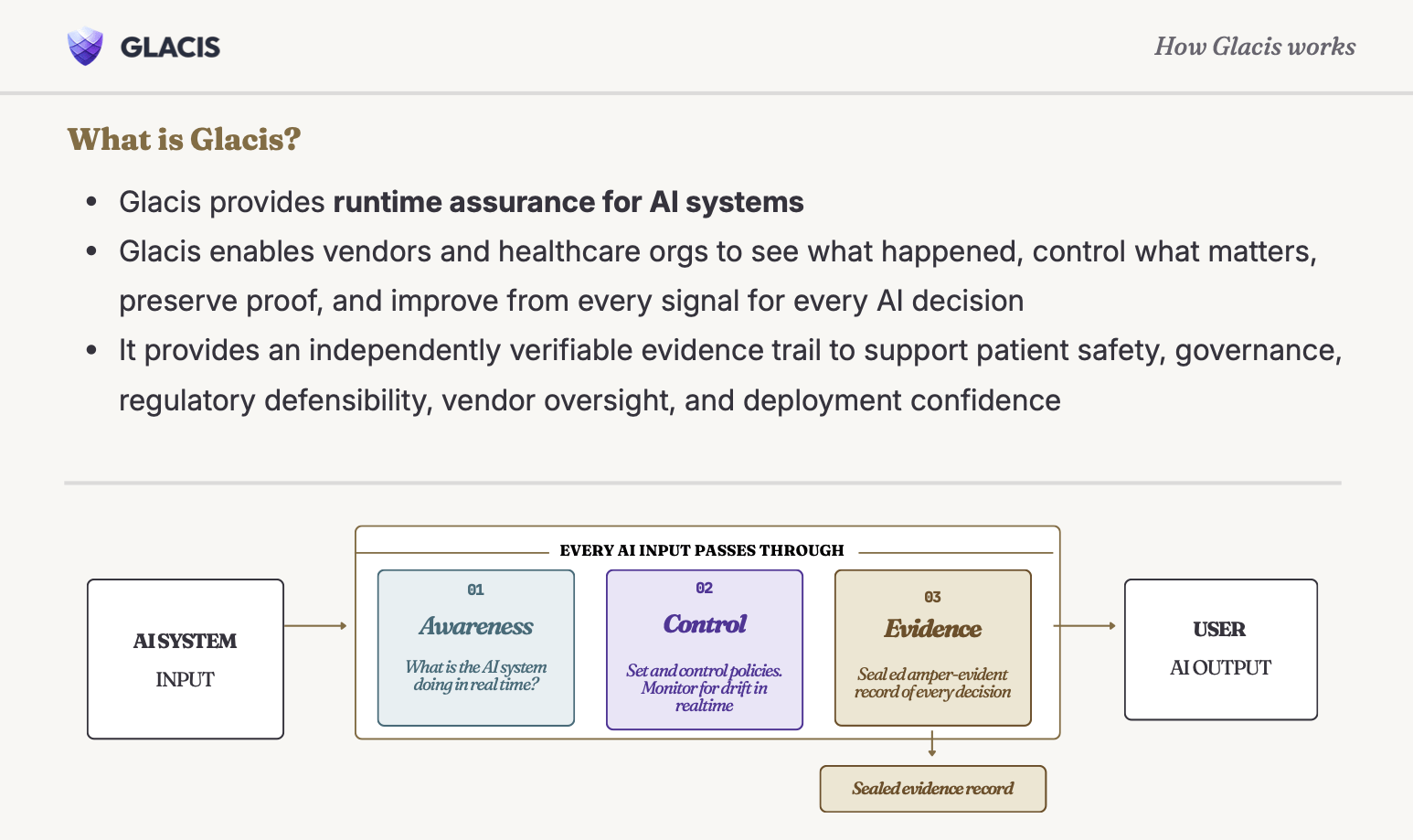
GLACIS developed the OVERT standard, Observable Verification Evidence for Runtime Trust to close that gap. OVERT is an open specification that defines how to produce cryptographic proof that AI safety controls actually ran. It is a technical infrastructure that any health system, AI vendor, or auditor can adopt.
Today, when a health system asks an AI vendor to demonstrate that its safety controls are working, the vendor produces its own logs. Those logs are self-attested. There is no independent mechanism to verify that what the vendor says happened is what actually happened. Evidence produced under the OVERT standard is cryptographically signed and independently verifiable, so a health system, regulator, or auditor can confirm that a specific safety control was active at a specific moment.
The standard is already crosswalked to the NIST AI Risk Management Framework, ISO 42001, the EU AI Act, and other major governance frameworks. For health systems navigating multiple regulatory requirements simultaneously, that crosswalk means that evidence generated once can be mapped against multiple compliance obligations automatically.
For AI vendors, OVERT offers a credible, third-party-verifiable way to demonstrate that their product meets governance requirements. In a procurement environment where health systems are increasingly skeptical of self-reported safety claims, vendors who can produce OVERT-compliant evidence have a structural advantage.
The standard is available at overt.is. GLACIS implements OVERT natively, but any organization can adopt the standard independently.
Shannon describes GLACIS as a continuously learning evidence layer, an infrastructure that sits inside an AI vendor’s or health system’s own environment, including their own private cloud, so protected health information never leaves the organization. That design decision matters. One of the most consistent barriers to adopting any AI observability tool in healthcare is the concern that monitoring requires sending sensitive data somewhere else. GLACIS was built to remove that barrier entirely.
The platform works across three core functions: visibility->enforcement->proof. First, the vendor or organization establishes their own verified baseline by defining what “good” looks like for the AI system for their specific deployment. For an AI mental health chatbot, that might mean specifying that any crisis trigger must be escalated to a human clinician, that the system must never offer clinical decision-making guidance, and that model accuracy must remain within a defined range. That baseline is customized to the use case because a generic standard applied across every deployment is not actually a standard; it is a placeholder.
Second, GLACIS monitors every inference in real time against that baseline. Every AI decision is assessed as it happens. If a safety control fails or a policy is breached, it can be flagged and enforced at that moment based on the vendor or organization’s own policies, not discovered three months later in a review.
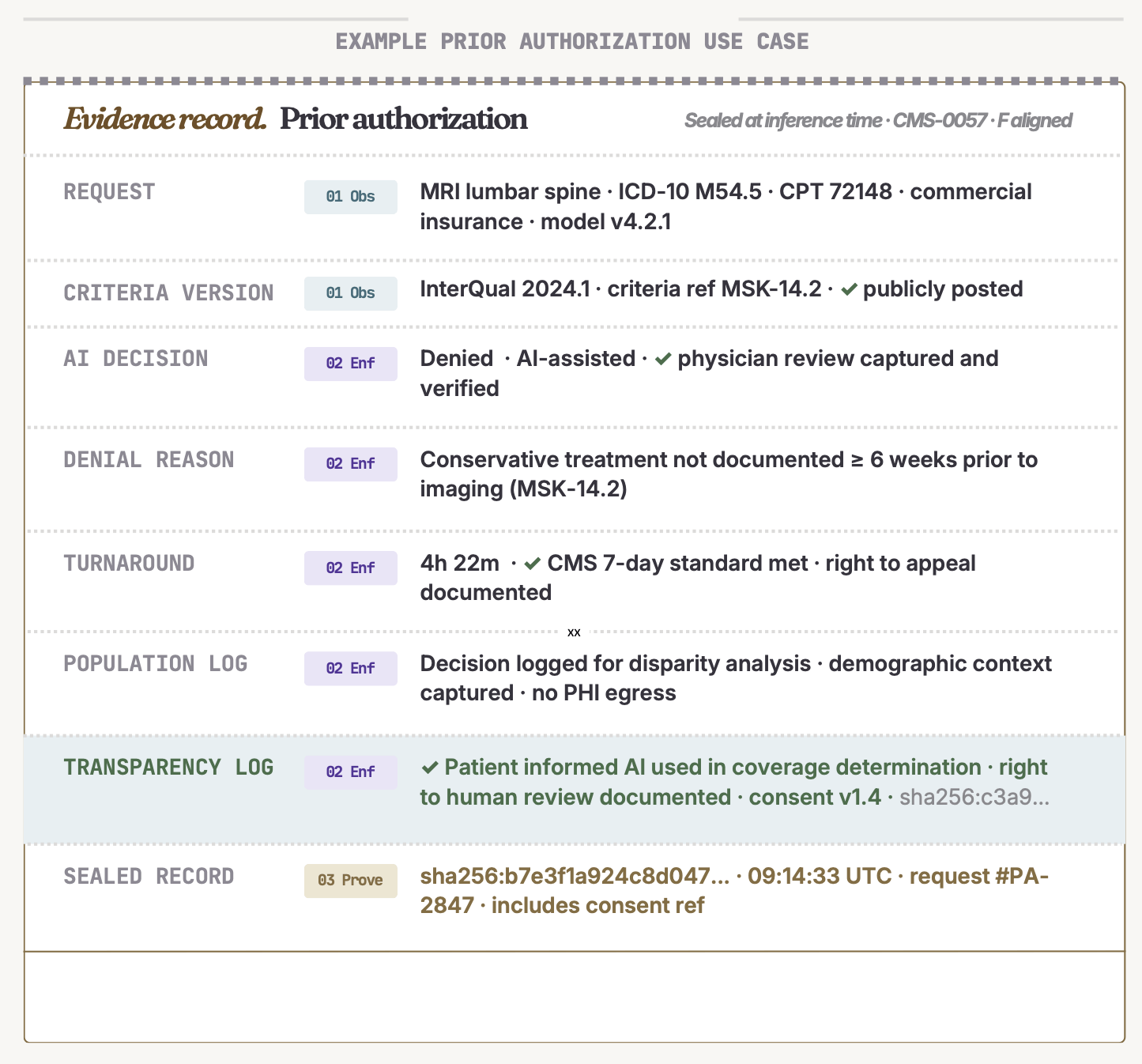
Third, the platform generates a cryptographic, third-party-verifiable record of what occurred at each inference point. Shannon calls this an evidence bundle, a legally defensible record that can be used in regulatory submissions, audit responses, or litigation. The record is not generated by the vendor. It is independently attested. If something goes wrong and the question is what the system was doing at that exact moment, GLACIS can answer it in a way that cannot be altered after the fact.
From compliance checkbox to compliance by design
There are currently more than 35 AI governance frameworks in circulation. They include the EU AI Act, Colorado’s AI Act, ISO 42001, the NIST AI Risk Management Framework, and a growing body of state-level regulation that continues to evolve. Keeping pace with all of them, mapping organizational data against each requirement, and identifying gaps is work that most health systems and AI vendors are not resourced to do consistently.
GLACIS’s approach to this problem is to make compliance a byproduct rather than a separate project and line item. The platform includes a compliance agent that continuously tracks regulatory changes and maps the data GLACIS is already collecting against each applicable requirement. Organizations can see in real time where they meet requirements, where gaps exist, and what they need to address. When a regulation changes, the mapping updates.
“Compliance is built in and a byproduct of collecting this data, bringing other value as well,” says Shannon.
That framing matters. Compliance pursued as a standalone, and bolted on objective tends to produce checklists. Compliance that emerges from infrastructure built for other purposes, continuous monitoring, drift detection, safety enforcement, produces evidence that is both more complete and more credible. For regulated medical device companies navigating the FDA’s Predetermined Change Control Plan requirements, which govern how model changes affect a device’s regulatory status, the difference between generating evidence retrospectively and capturing it continuously can represent hundreds of hours of work and significant cost.
The co-design opportunity
Something Shannon is watching with interest is a shift in how some health systems are approaching vendor procurement. Rather than evaluating vendor-provided claims, a small number of organizations have begun specifying what independent evidence they expect vendors to produce as a condition of consideration. In addition, some accreditation bodies like URAC have AI accreditation standards and others are following suit.
In one example she describes, a health system told prospective AI vendors that if they wanted to be evaluated, they needed to implement trust verification infrastructure and submit evidence generated by that infrastructure, not by themselves.
“If you want us to consider you, you need to implement this trust infrastructure,” Shannon explains. “And then we’re going to look at the independent evidence generated on our end. If that passes, we’ll let you through the first pass.”
This is a meaningful structural shift. It moves the governance question from a negotiation over claims to an assessment of independently verified performance. And it creates a clear incentive for AI vendors to build accountability infrastructure early, because organizations that have done so will have a faster path through procurement with health systems that require it.
That is the direction Shannon believes the field needs to move: not just more and better frameworks, but infrastructure that makes responsible AI deployment something you can measure, improve and show evidence for rather than something you assert. It is also the direction DiMe is working toward with industry partners through Operationalizing AI Governance in Healthcare on closing the runtime gap as a shared field problem rather than a product category.
What health systems and AI vendors should be thinking about now
The most consistent gap Shannon hears about in conversations with health system and payor leaders is not a lack of pre-deployment rigor. Most organizations are investing heavily in vetting vendors, reviewing model cards, running pilots, and working through procurement questions. That work is necessary. But it is also, in Shannon’s view, only the beginning of the actual governance challenge.
“Pre-deployment is really just the starting place,” she says. “The more important part is post-deployment, after the AI actually goes live. That’s when you have no idea how it’s actually going to perform in your population.”
The second gap is less often discussed: a widespread lack of awareness that the runtime layer exists as a distinct governance problem. Many of the people responsible for AI governance decisions, writing procurement requirements, sitting on review committees, approving deployments, are operating at the level of model performance and aggregate accuracy. Those metrics matter. But they do not tell you what the AI is doing at the moment it is interacting with the end user. They do not tell you whether the safety controls are active for that specific interaction. And they do not tell you, if something goes wrong, what actually happened.
That is the layer GLACIS was built to make visible. Not because health systems and AI vendors have failed to take governance seriously, but because the infrastructure to do it well has not existed until now.
DiMe is working with industry partners across health systems, life sciences, and the AI community to help the field with shared governance tools, rather than something that is a competitive advantage. Join us: Operationalizing AI governance in healthcare.
To learn more about GLACIS, visit glacis.io.

