
Apple ResearchKit is already accelerating research by attracting huge numbers of people to participate in medical research for the first time. In this blog we share our experience using Active Tasks included in ResearchKit to assess cognitive function, and offer recommendations for how this critical resource can continue to evolve to further advance research and contribute to new clinical insights.
As a member of DiMe’s Scientific Leadership Board, I am excited about DiMe’s commitment to supporting the field of digital medicine through advancing best practice, collaboration, and knowledge sharing. In that spirit, it is an honor to be our first guest blogger, sharing a post originally written with Matt Johnson for Mount Sinai’s Health Data and Design Innovation Center blog.

‘Big Tech’ Comes for Healthcare
Advancements in digital medicine have created a shift in the flow of health data and information, placing a stronger emphasis on the technologies used for measurement and intervention. Tech giants are taking notice, as both hardware and software are central to accelerating this transformation. The participation of technology-native companies into the healthcare ecosystem stands to benefit all stakeholders. For example, their resources and power for positive change have played a role in helping consumers get more portable access to medical records from entrenched interests like the dominant electronic medical record vendor, Epic.
Just in the past year, Apple has:
- Opened their Health Records API to developers
- Received FDA clearance for EKG and arrhythmia notifications on the Apple Watch 4
- Enrolled 400,000 people in an arrhythmia-related research study
- Released version 2 of ResearchKit
With these moves, Apple has the potential to become a digital platform for health, allowing 3rd party developers to build an app ecosystem for healthcare the way they have already done for mobile (among other possible goals).
In this post we focus on Apple’s ResearchKit, one component of the Apple Health platform. We share some benefits and challenges we encountered while building an app for N-of-1 trials using ResearchKit, and use this experience to frame specific recommendations for technology organizations involved in the digital transformation of medicine.
ResearchKit Background
ResearchKit has proven to be a valuable resource in leveraging mobile technology for medical research. Not only does it allow researchers to develop and implement digital studies more rapidly, but it also moves studies out of the clinic and into the pocket of every iOS user. Early examples of studies built using ResearchKit, like the Parkinson’s mPower study, have demonstrated new opportunities for researchers to engage far broader audiences than previously possible. People that want to participate in research, but are unable to travel to an academic medical center, have new avenues for volunteering.
So, why is ResearchKit important for researchers?
ResearchKit makes it easier to collect data and information for research studies in a standardized way. Tools for electronic consent and administering questionnaires allow researchers to implement several of the most basic tasks of any study. The myriad sensors and functionality already baked into our smartphones are also accessible through ResearchKit, enabling novel measurement instruments. For example, the Parkinson’s mPower app uses the microphone to record and assess signs of tremor in the voice of participants, while the multitouch screen assesses the manual dexterity and speed of participants’ left and right hands during a tapping exercise.
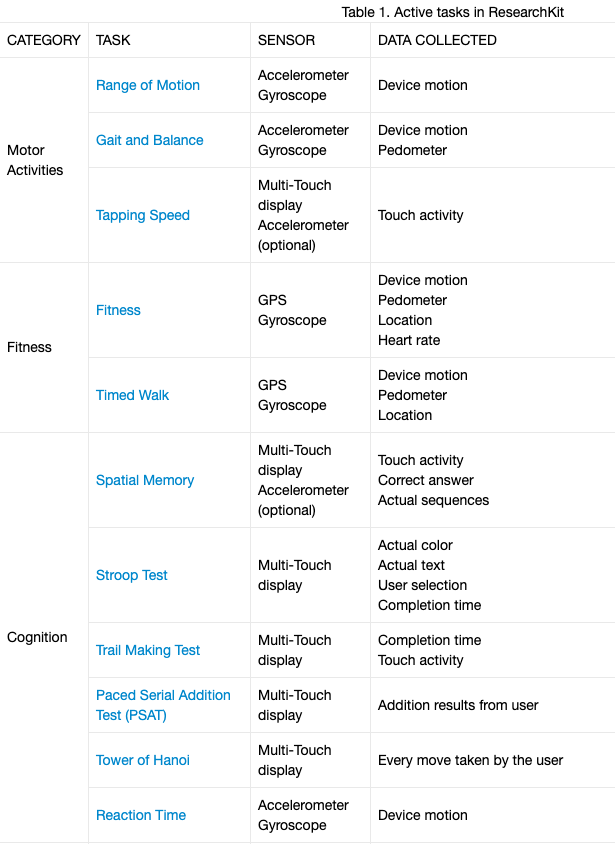
ResearchKit includes 19 predefined sensor-based assessment instruments, called ActiveTasks, for domains including motor activity, fitness, cognition, speech, hearing, vision and dexterity. These tasks often mirror analog counterparts, such as the 9-hole peg test for manual dexterity, or the Amsler Grid test used to detect vision problems. The tasks can be used as-is, or as building blocks to create customized tasks.
Our experience implementing the ResearchKit Stroop Test
The Stroop Test is one of the ActiveTasks available for researchers using ResearchKit for digital studies. This test was originally developed in 1935 and continues to be used to evaluate executive functions in conditions ranging from Dementia to ADHD. Like many of the tests in Apple’s Research Kit, the validated paper-based test needed to be adapted for use on iOS devices. As is typical during conversion processes, some decisions need to be made — size and placement of buttons, how to deal with user mistakes, choosing appropriate default or customizable parameters, etc.

There are two key differences between the ResearchKit Active Task and the original Stroop test that render the straightforward analysis originally described by Stroop (a difference in means) impossible to calculate (details and history of the Stroop Interference Test). Instead, we had to choose a new metric to evaluate executive function. There are two measures collected by the ResearchKit variation of the Stroop test:
- Accuracy — the percentage of correct answers
- Response time — the speed at which the user completes the assessment
Evaluating either of the measures individually do not capture the intent of the task (e.g. you can trivially get perfect accuracy by going very slowly; alternatively, you can respond very quickly and have poor accuracy). A good measure of executive function from data collected from this ActiveTask must integrate accuracy and reaction time into a single measure. As it turns out, there is a whole literature on methods to combine speed and accuracy measures of performance in cognitive research!
In our application, we decided to use the rate correct score (RCS) from Wolf & Was 2006. The score is calculated by dividing the number of correct responses by the total time to complete the test. This seems reasonable, and it performed well across a variety of conditions when compared to other metrics.
Importantly, there is no right way to implement and score the Stroop Test on a mobile device. The assessment called the Stroop Test in ResearchKit is different from the original paper-and-pencil version of the test. Although it departs from a validated test design, it also collects additional measurements which may broaden research findings. The Stroop Test can be used in different contexts — different conditions, patient populations, and settings. While there is no single implementation across the board, there may be better ways in specific contexts of use. What is desirable, is that if we use the Apple ResearchKit Stroop implementation, another researcher can compare their results to ours; and an important part of that consideration is how they choose to score the test.
Recommendations
- The Apple ResearchKit team should provide a list of recommended or suggested analyses for each of the predefined ActiveTasks.
Rationale: To facilitate comparison, which is an important component to achieving meaningful research conclusions, and help to prevent developers or researchers from analyzing results based on incomplete evaluation metrics. By including recommended or suggested analyses with ActiveTasks, Apple could go even further by promoting standardization and interoperability of research results.
2. Standardize the predefined ActiveTasks developed by Apple
Rationale: To limit unnecessary variability, parameters across all predefined active tasks should be standardized. For example, the duration of the countdown timer and whether the device vibrates before the start of a task should be consistent for all predefined tasks developed by Apple. Default values that are chosen for task-specific parameters, should also be well-thought through and vetted with supporting evidence or rationale. This would likely encourage adoption as it would provide researchers greater confidence in the outcome of the tasks and limit variability in various task-specific parameters. With more researchers using the same predefined active tasks, these tasks are more likely to become a standard and provide a strong foundation for further research.
Accelerating Research Through Collaboration
For ResearchKit, and any emergent frameworks, better guides for implementation of certain features and transparency regarding design choices and analytic approaches are critical to driving adoption by developers and to strengthening the science of researchers.
Where vendors and manufacturers are unable to make recommendations on analytic approaches or support knowledge sharing across study teams, multi-disciplinary, disinterested organizations could champion knowledge sharing and transparency initiatives. For example, the Digital Medicine Society (DiMe), a 501c3 that serves as a professional society for those who practice in the digital era of medicine has established a crowdsourced library of digital measures used as study endpoints in industry sponsored studies to promote knowledge sharing and collaboration.
We are excited to be using ResearchKit and are grateful to the developers that have contributed to the open-source platform. We’d welcome feedback and new ideas from others in the research community that are early adopters of ResearchKit (tweet us @zimmeee and @immadbananas, or send email to info@hd2i.org).

